Longformer: The Long-Document Transformer
22 Apr 2020Iz Beltagy, Matthew E. Peters and Arman Cohan. Longformer: The Long-Document Transformer. arXiv:2004.05150, 2020.
Intro
본 논문은 기존 Transformer기반 모델의 한계를 설명하며, 긴 텍스트에 대해서 $O(N)$의 복잡도로 임베딩하는 방법을 제안한다.
Transformer에서 사용되는 self-attention은 아래와 같이 디코딩 시 전체 입력 텍스트를 보기 때문에 $O(N^2)$의 복잡도로 임베딩을 수행하여 굉장히 많은 computation을 필요로 한다. 또한 기존 BERT 기반의 모델들은 long context를 커버하기 위해 truncate된 시퀀스만을 사용하는데 일반적으로 512개 token을 limit으로 가진다. 그렇기 때문에 전체를 고려하는 cross-partition information이 떨어지게 되고, 그에 따라 복잡한 모델 아키텍쳐로 이를 극복하려 한다.
Longformer는 문장이 길더라도 전체 텍스트를 고려하는 whole contextual representations를 학습하며, task-specific한 모델 아키텍쳐에 의존하지 않고 성능을 높이고자 한다.

Transformer의 self-attention 동작 원리
Long-Document Transformers
긴 텍스트를 처리하는 기존 연구들은 크게 두 가지로 나뉜다.
첫번째 방법은 긴 텍스트를 left-to-right로 이동하며 Chunk 단위로 쪼개어 임베딩 한 뒤, 이를 다시 시퀀스로 임베딩하는 방법이다. 이는 autoregressive language modeling에는 적합하지만, 다시 시퀀스로 임베딩하는 과정에서 정보 유실이 일어나기 때문에 bidirectional context를 필요로 하는 테스크에 transfer하기에는 적합하지 않다. Transformer-XL, Adaptive Span Transformer 등이 이러한 방식의 연구들이다.
두번째 방법은 general한 sparse attention pattern을 찾아 attention에 필요한 복잡도를 낮추는 방법이다. Longformer는 이러한 방식의 연구에 속하며, $O(N)$만에 수행하는 attention 방식을 제안한다.
Attention Method
본 논문에서는 아래와 같은 다양한 attention 방식을 제안한다.
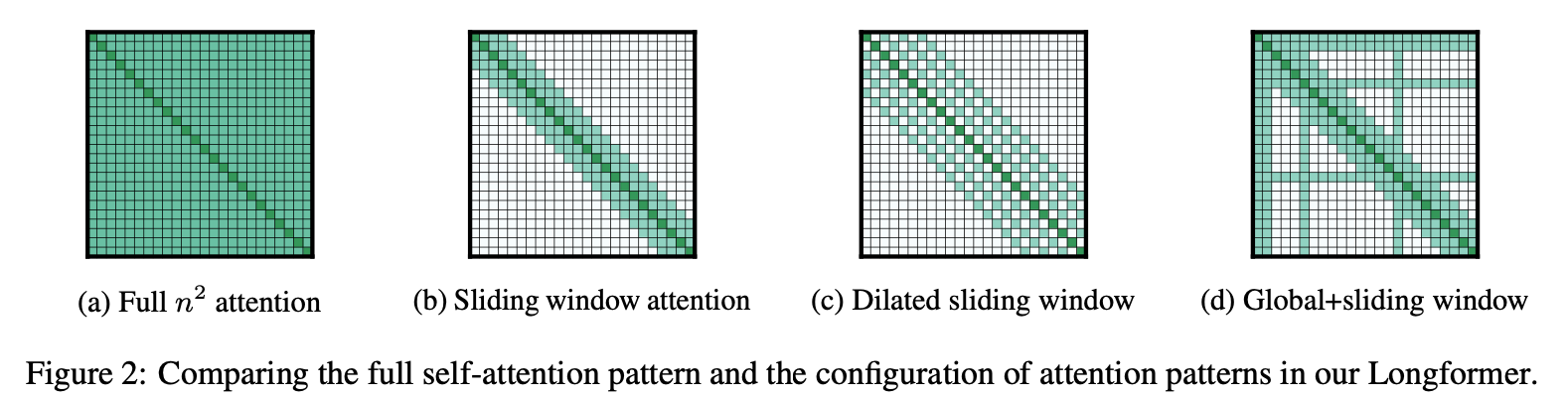
Sliding Window
크기가 $w$인 sliding window 내에서만 attention을 수행하며 이는 텍스트 길이 $n$에 대해 $O(n \times w)$의 복잡도를 가진다.
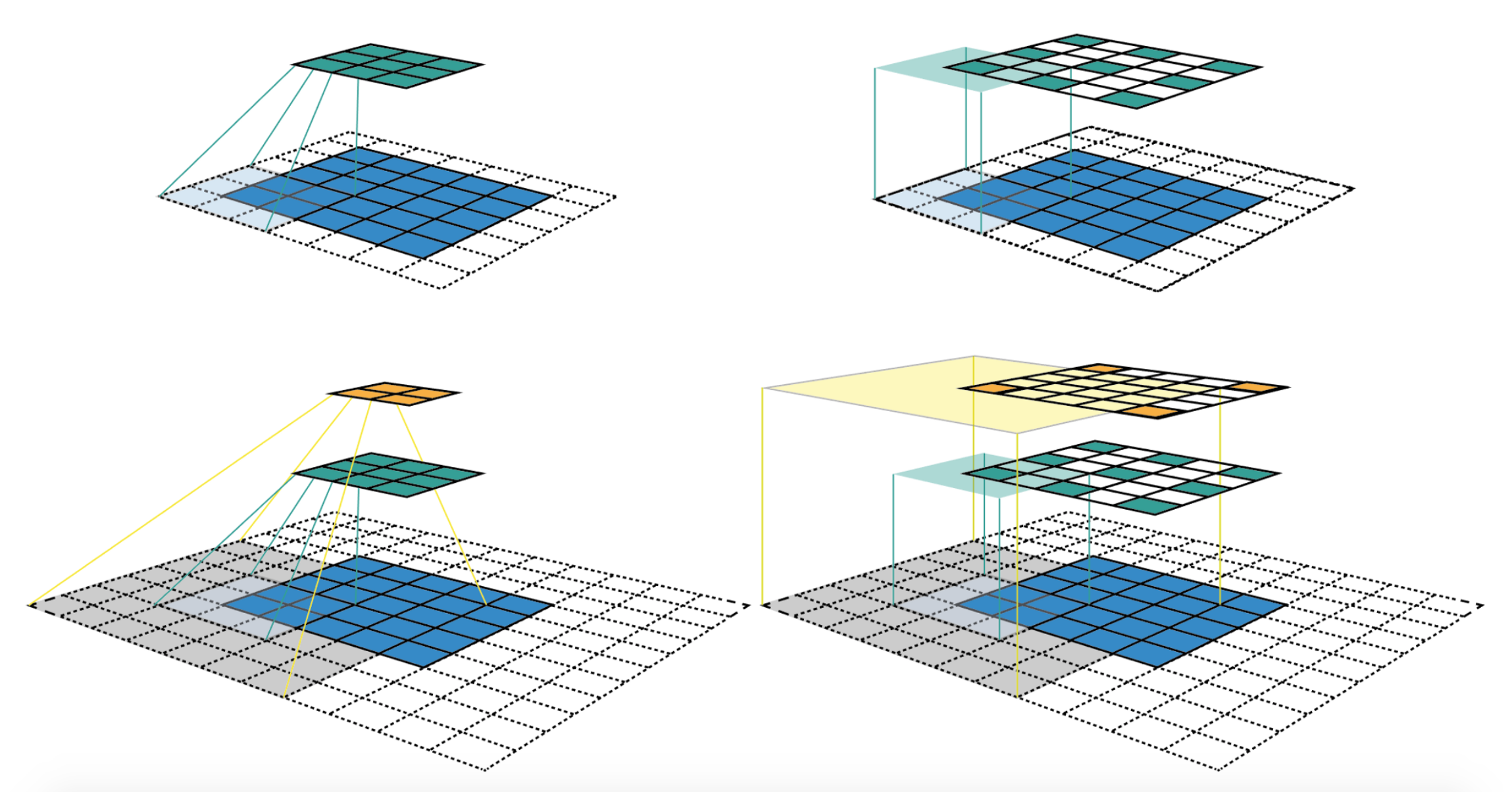
이러한 방식은 아래와 같이 CNN에서 layer가 쌓임에 따라 각 커널이 더 넓은 receptive field를 가지는 것에서 착안하였다.
 Window size $w$가 2일 때, 아래 그림과 같이 하나의 layer가 쌓일수록 좌우 양끝에 각각 $\frac{w}{2}$ 만큼 receptive field가 넓어지게 된다.
Window size $w$가 2일 때, 아래 그림과 같이 하나의 layer가 쌓일수록 좌우 양끝에 각각 $\frac{w}{2}$ 만큼 receptive field가 넓어지게 된다.
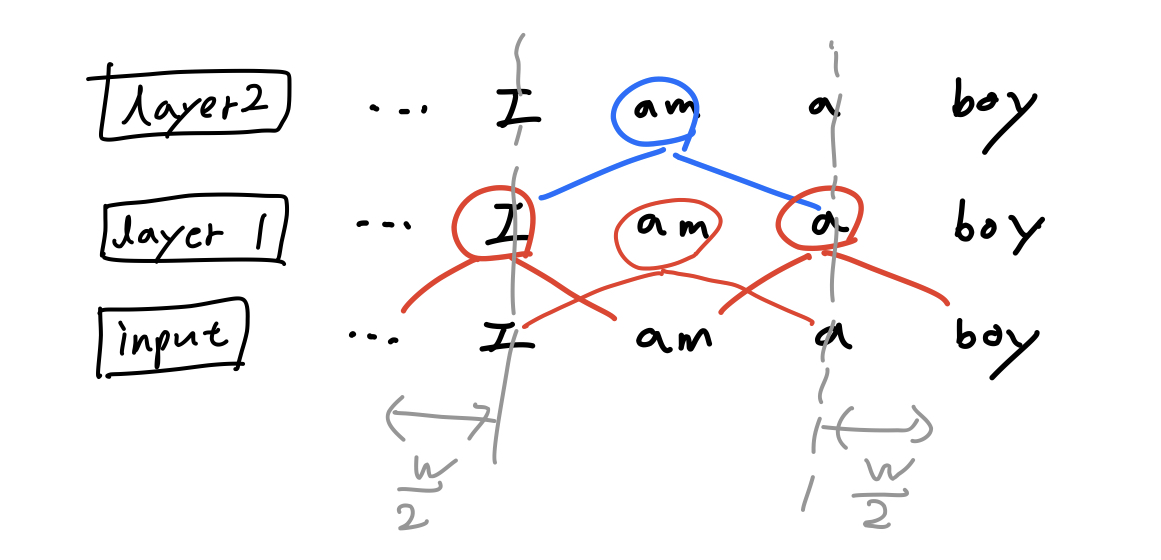 따라서 layer가 $l$개일 때 $l \times w$ 만큼의 receptive field size를 가진다.
따라서 layer가 $l$개일 때 $l \times w$ 만큼의 receptive field size를 가진다.
Dilated Sliding Window
Receptive field를 좀 더 효율적으로 넓히기 위해 dilated sliding window를 사용한다. 이 방식은 아래와 같이 window를 dilated size만큼 확장시켜 사용하는 Dilated Convolutions에서 착안되었다.
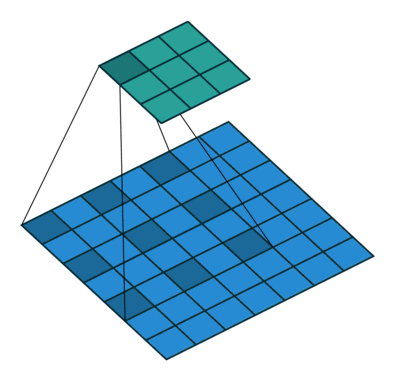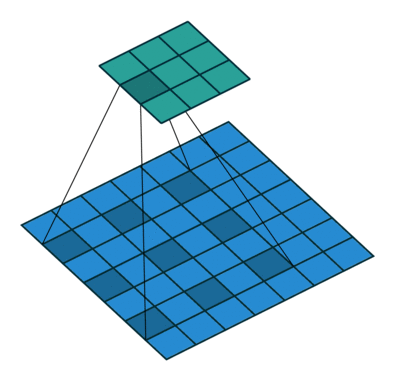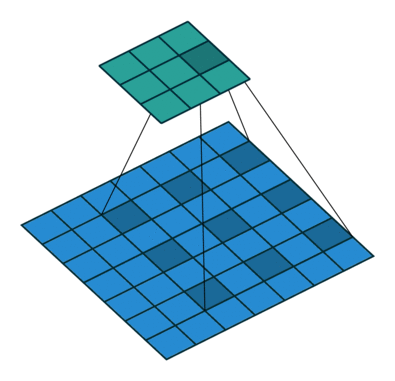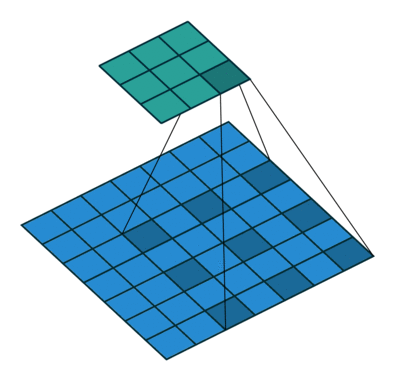 Window size $w$가 2이고 dilation size $d$가 2일 때, 아래 그림과 같이 하나의 layer가 쌓일수록 좌우 양끝에 각각 $\frac{w \times d}{2}$ 만큼 receptive field가 넓어지게 된다.
Window size $w$가 2이고 dilation size $d$가 2일 때, 아래 그림과 같이 하나의 layer가 쌓일수록 좌우 양끝에 각각 $\frac{w \times d}{2}$ 만큼 receptive field가 넓어지게 된다.
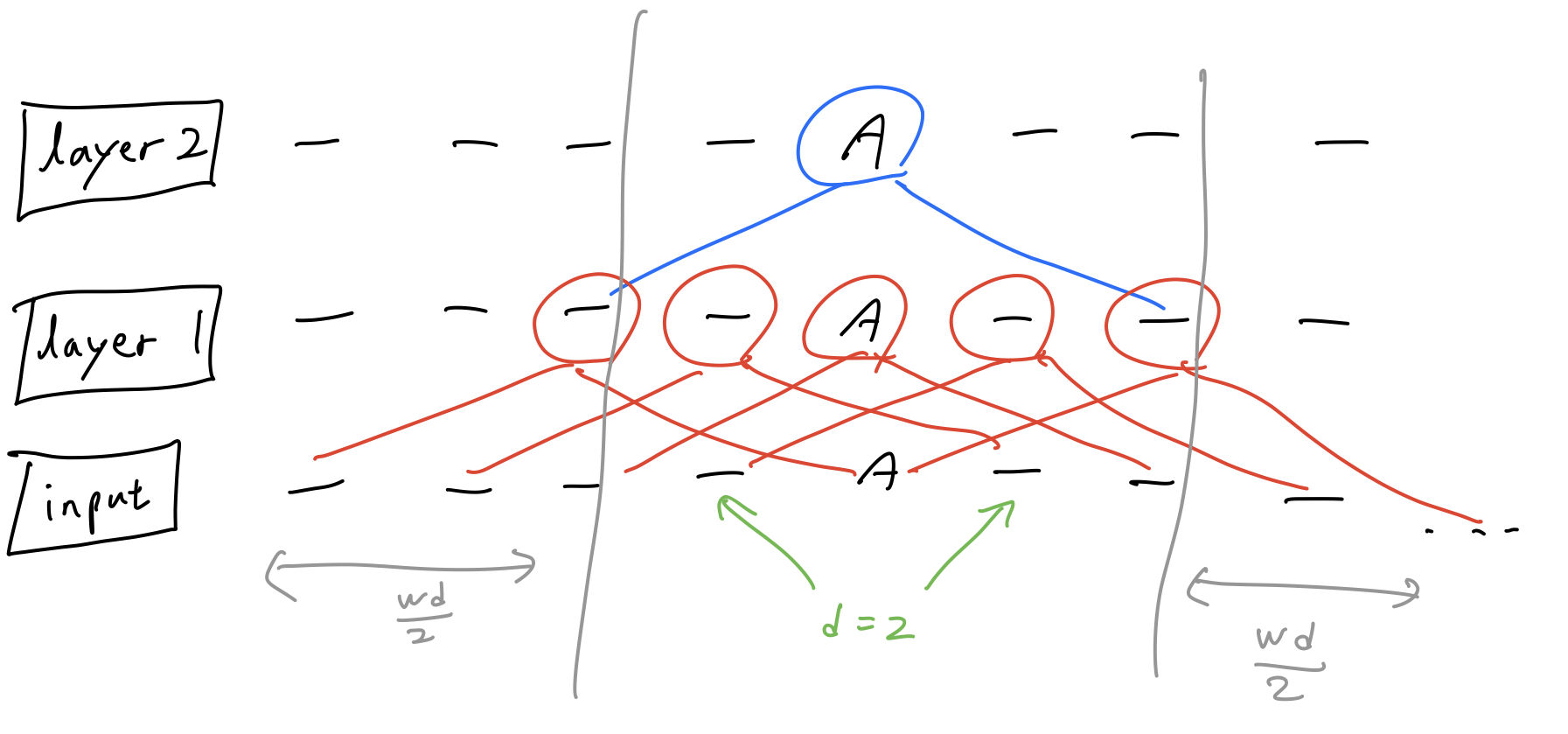 따라서 layer가 $l$개일 때 $l \times d \times w$ 만큼의 receptive field size를 가진다.
따라서 layer가 $l$개일 때 $l \times d \times w$ 만큼의 receptive field size를 가진다.
Global Attention
BERT 기반의 모델들은 language modeling 학습과 task 학습 시에 서로 다른 방식으로 context를 바라본다.
먼저 Masked Language Modeling의 경우는 local context를 바라보며 가려진 단어를 예측한다. 반면 classification의 경우엔 [CLS] 와 같은 토큰을 이용하여 whole context를 바라본다. 위에서 언급한 Sliding Window와 Dilated Sliding Window 방식은 local context만을 바라보기 때문에 긴 텍스트에 대한 task에 대해선 부족한 부분이 있다.
따라서 본 논문에서는 input 위치에 토큰을 몇개 지정하고 이들이 global attention을 수행하도록 한다. 이 토큰들은 입력 전체에 대한 global attention을 수행하지만, 긴 텍스트 길이에 비해 토큰의 수가 매우 적기 때문에 여전히 $O(N)$ 복잡도로 수행하게 된다.
Linear Projections for Global Attention
Transformer 구조에서 attention은 $Q$, $K$, $V$의 linear projection으로 계산되었다. 위에서 언급된 sliding window 기반의 attention과 global attention를 위해 각각 $Q_{s}$, $K_{s}$, $V_{s}$와 $Q_{g}$, $K_{g}$, $V_{g}$ 두 세트로 나누어 attention을 계산한다.
Experiments
본 논문은 크게 2가지 방식의 평가를 진행한다. 첫째로 모델 자체의 임베딩 평가를 위해 Autoregressive Language Modeling을 수행한다. 두번째는 다양한 Downstream 테스크에서의 평가를 위해 Pretraining 후 테스크 별로 Finetuning 한다.
Autoregressive Language Modeling
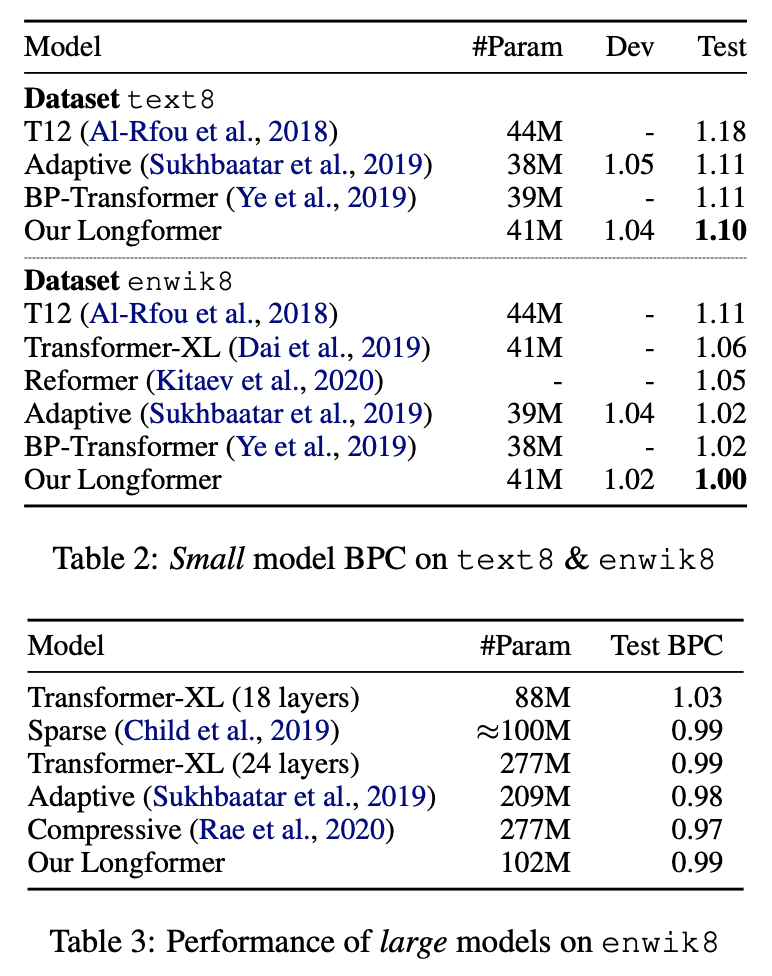
긴 텍스트에 대한 임베딩 평가를 위해 일반적으로 character/token 단위의 Language Modeling을 수행한다. 본 논문에서는 이를 위해 text8와 enwik8 데이터셋으로 평가하였으며 SOTA를 달성하였다.
본 테스크 학습에는 dilated sliding window attention를 사용하였다.
Pretraining and Finetuning
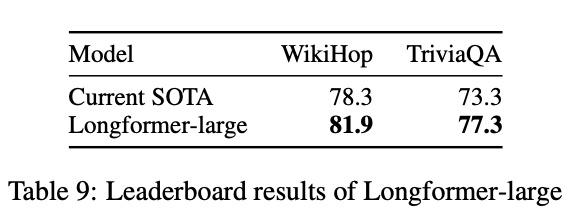
요즘 NLP 연구는 BERT와 같은 task supervision 모델을 finetune하는 방식이다. 본 논문은 긴 텍스트에 강건한 task supervision 모델을 목표로 하며 다양한 테스크에 대해 실험을 진행하였다.
먼저 Longformer의 pretraining을 위해 RoBERTa 체크포인트로부터 시작하여 학습한다. 본 학습은 sliding window attention를 사용하였다. 이후, 각 테스크에 따라 global attention을 이용하여 학습하였으며 아래와 같이 좋은 성능을 보였다. 특히 Longformer-large 모델의 경우, WikiHop과 TriviaQA 데이터셋에서 SOTA를 달성하였다.