Graph Convolutional Networks for Text Classification
05 May 2020Liang Yao, Chengsheng Mao, Yuan Luo. Graph Convolutional Networks for Text Classification. In AAAI, 2019.
본 논문은 GCN을 Text Classification에 적용한 논문이다. 이를 위해 문서를 Graph로써 어떻게 정의할지를 소개하고, 성능 비교를 통해 기존 방법과 GNN의 차이를 설명한다.
Graph Convolution Networks (GCN)
본 논문은 다양한 GNN 기법 중 Graph Convolution Networks을 기반으로 문서 분류를 진행한다. 따라서 먼저 GCN의 정의를 살펴보고자 한다.
Graph $G$는 Node와 Edge로 구성되며 $G = (V, E)$로 표현할 수 있다.
Node는 n개의 Entity를 나타내고 $V(\mid V \mid = n)$로 정의하자.
각 노드 별로 feature가 m차원일 때, 입력노드의 feature 행렬인 $X$는 $X \in \mathbb{R}^{n \times m}$를 따르고, 각 vector는 $x_v \in \mathbb{R}^m$와 같다.
GCN에서는 입력노드의 feature 행렬인 $X$ 이외에도, Graph $G$를 표현하는 인접행렬 $A$와 degree matrix $D$를 이용한다. ($D_{ii} = \sum_{j} A_{ij}$)
이 때, $A$에서의 대각성분은 학습 시 self-loops을 위해 1로 설정한다. ($A = A + I$)
GCN을 비롯한 GNN 네트워크들은 주변 이웃 노드 간의 aggregate 과정을 통해 layer가 정의된다. 때문에 one layer일 경우, 인접한 이웃 노드의 정보만을 학습하게 될 것이다. GNN의 layer가 쌓일수록 넓은 범위의 노드 정보까지 학습하게 되며 이는 아래와 같은 수식으로 표현할 수 있다.
첫 layer가 $k$ dimension일 때 아래와 같이 정의된다. ($L^{(1)} \in \mathbb{R}^{n \times k}$)
이 때, $\tilde{A}$는 normalized symmetric adjacency matrix이며, $W_0 \in \mathbb{R}^{m \times k} $이다.
이를 여러 층 쌓아 일반화 하면 아래와 같이 정의된다.
Text Graph Convolution Networks (Text GCN)
Node는 문서와 단어들로 구성되며 $\mid V \mid$는 number of documents + number of vocabulary와 같다.
Edge는 document-word edge와 word-word edge로 구성된다. Figure1에서는 각 문서에 등장하는 단어를 연결한 document-word edge를 검은 실선으로 연결하였고, 전체 코퍼스의 word co-occurrence를 이용한 word-word edge는 회색 실선으로 연결하여 표현하였다.
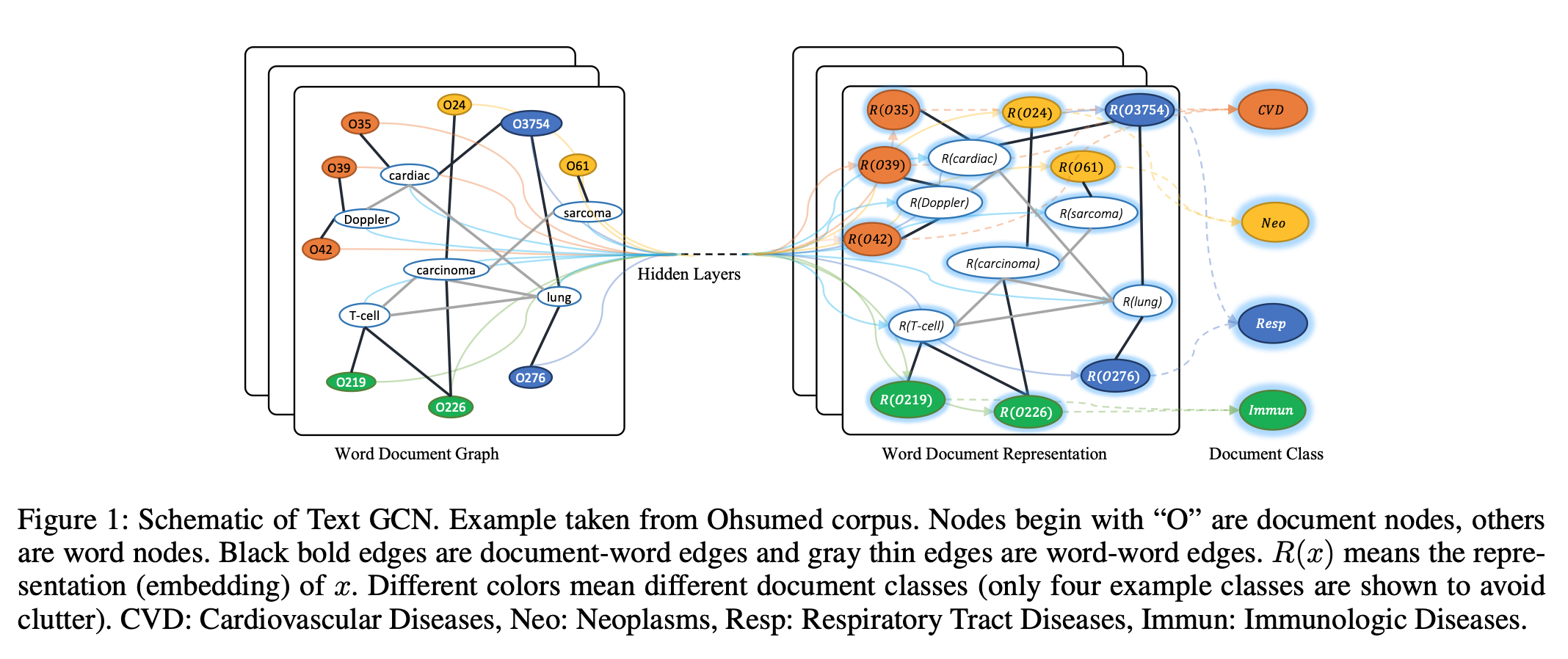
이렇게 구성된 그래프를 인접행렬 $A$로 표현하여 학습한다. 이 때, $A$의 weight는 아래와 같이 정의한다.
문서-단어 간 weight는 TF-IDF를 이용하고, identity 성분은 self-loops를 위해 1로 설정한다.
단어-단어 간 weight는 fixed size sliding window를 통해 모든 코퍼스에서 단어 간 co-occurrence를 계산하고, 이를 기반으로 아래와 같이 point-wise mutual information(PMI)를 계산한다.
$\text{#}W(i)$는 전체 코퍼스에서 단어 $i$를 포함하는 sliding window의 개수이며, $\text{#}W$는 전체 sliding window의 개수를 의미한다.
PMI 값이 양수일 경우 단어 간 high semantic correlation을 의미하고, 음수일 경우 low semantic correlation을 의미한다. 따라서 인접행렬 $A$에서는 양수 값만을 사용한다.
이렇게 구성된 행렬을 이용하여 아래와 같은 softmax classicier를 구성하고 labeled document에 대한 cross-entropy를 학습한다.
이 때, 입력노드의 feature 행렬인 $X$는 모든 노드들에 대해 one-hot vector로써 표현하여 $X=I$로 사용하였다.
$F$는 output feature의 차원이고, $\mathcal{Y}_D$는 document label의 인덱스 집합이다.
Two-layer GCN
본 논문에서 구성된 GCN은 two-layer를 사용하였다. 노드 별로 aggregate하여 학습하는 GCN 특성 상, two-layer만 쌓아도 직접 연결되지 않은 두 노드 간의 정보를 학습할 수 있게 된다. 실제 GCN 논문(Kipf and Welling 2017)에서와 마찬가지로 two-layer가 one-layer보다 좋은 성능을 보임과 동시에 더 많은 layer를 쌓아도 더 이상의 성능 향상은 없었다.
Experiment
Test Performance
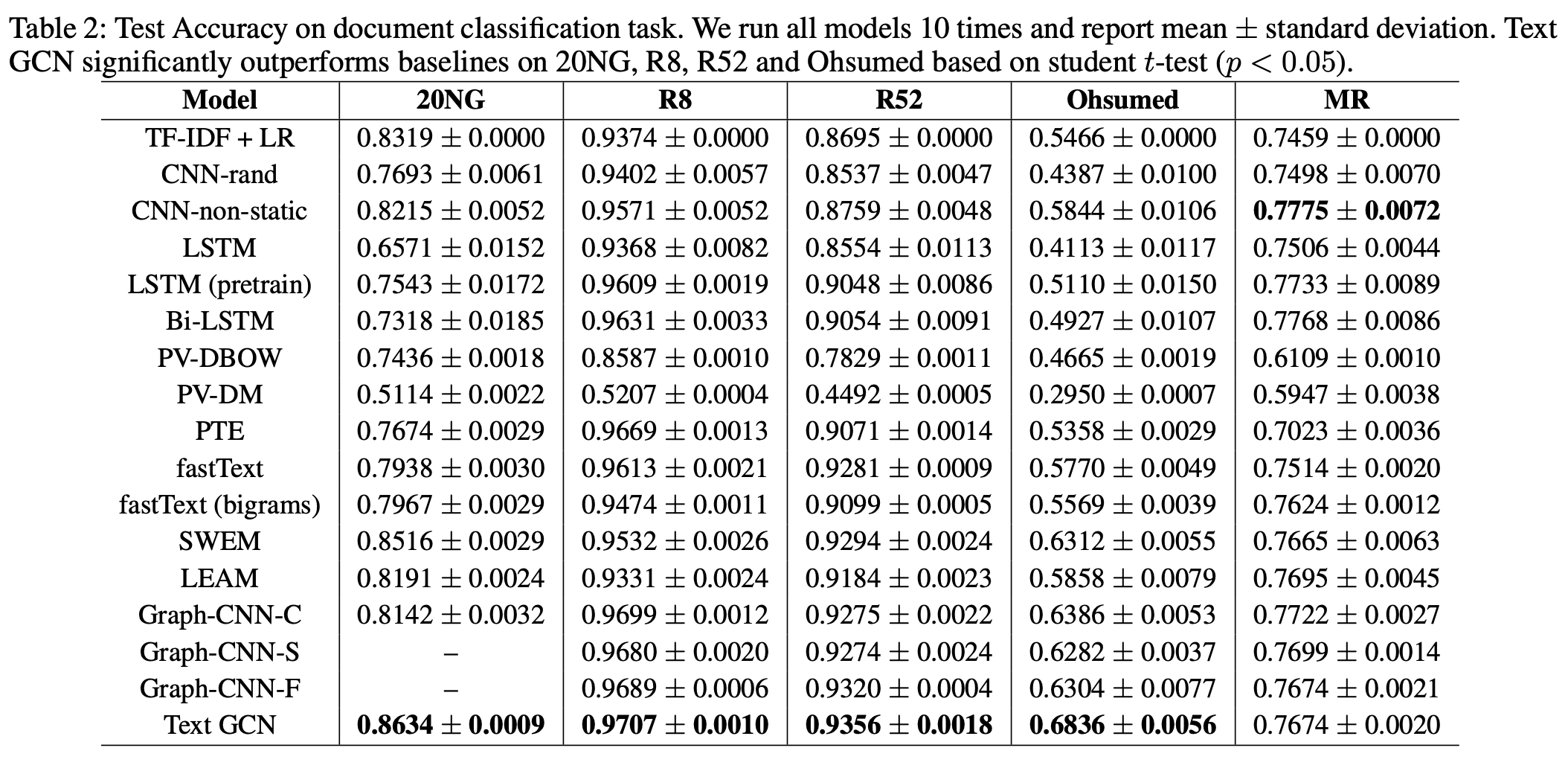
우선 카테고리를 가지는 데이터셋 5개에 대해 다른 모델과의 문서 분류 성능 평가를 한다. 그 결과 Table 2와 같이 영화 리뷰를 제외한 4가지 데이터셋에서 가장 높은 성능을 보였다.
본 논문에선 Text GCN이 좋은 성능을 보인 이유에 대해 아래 두가지 관점으로 해석한다.
- 텍스트 그래프는 document-word relation과 global word-word relation을 모두 반영할 수 있다.
- GCN은 Laplacian smoothing의 special case로써, 해당 노드 뿐만 아니라 second order neighbors까지 고려하여 가중합으로 학습한다.
반면, 영화리뷰(MR) 데이터셋에서 성능이 낮은 이유에 대해서는 아래와 같이 해석한다.
- GCN은 CNN이나 LSTM과 달리 word order를 고려하지 않는다.
- 문서의 길이가 매우 짧다.
- 때문에 document-word간 edge가 부족하다.
- 때문에 sliding window 수가 적어 word-word간 edge가 부족하다.
- CNN이나 LSTM은 pre-trained된 외부 word embedding을 사용하지만, Text GCN은 주어진 코퍼스 내에서만 정보를 학습한다.
이러한 단점을 반대로 생각하면 Text GCN 방식이 pre-trained 외 기법 중에서는 가장 좋은 성능을 보이고 있다고도 해석할 수 있다.
Effects of the Size of Labeled Data
더불어 가장 좋은 성능을 보인 몇가지 모델들에 대해 training data의 양을 변화시켜 보면서 비교하였다. Figure4는 20NG 및 R8 데이터셋의 training set을 1%, 5%, 10%, 20%만 사용하면서 test accuracy를 비교한다.
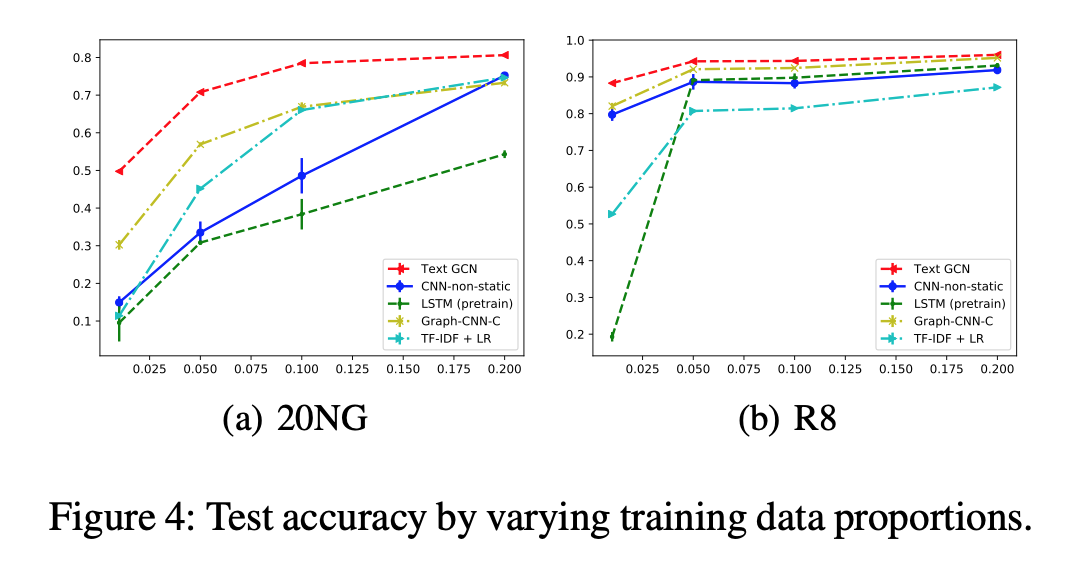
그 결과 TextGCN이 가장 강건한 성능을 보였다. 이는 GCN 논문(Kipf and Welling 2017)에서와 유사한 결과이며, 위에서 언급한 GCN의 두가지 장점에 의한 결과라고 주장한다.
Visualization
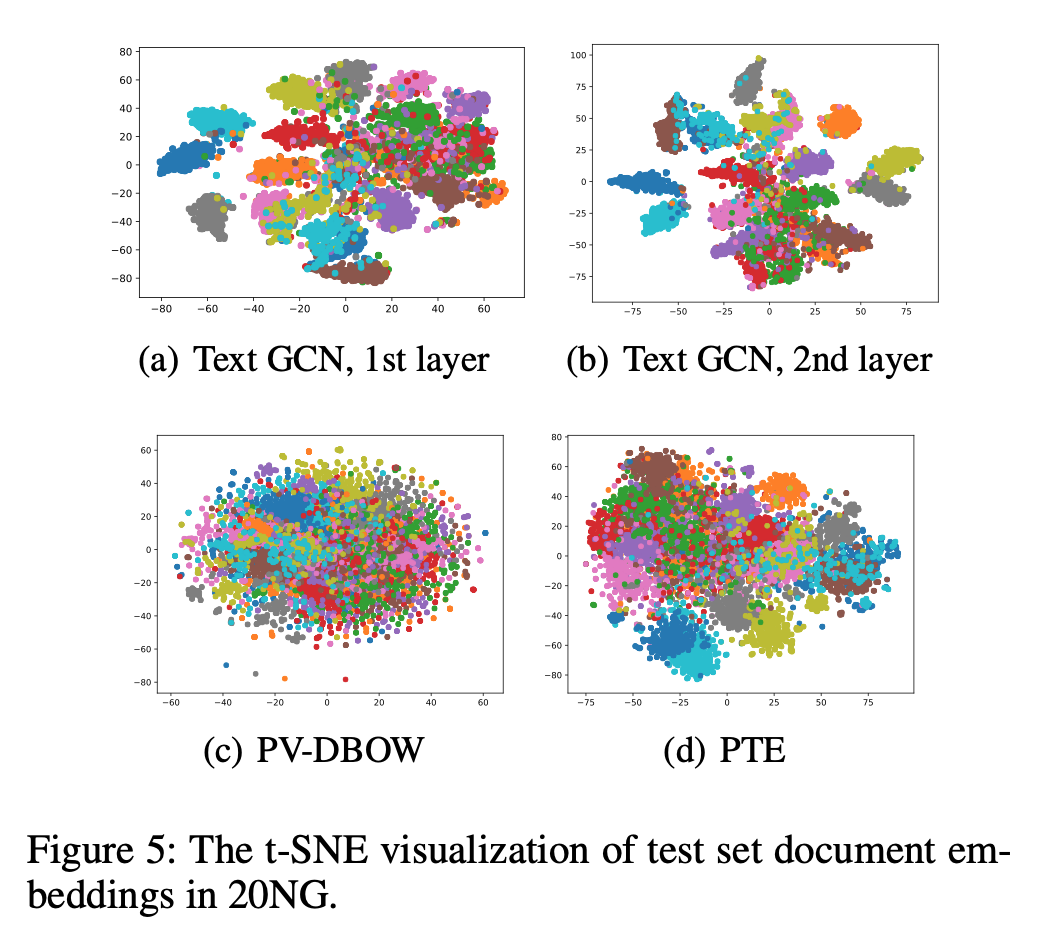
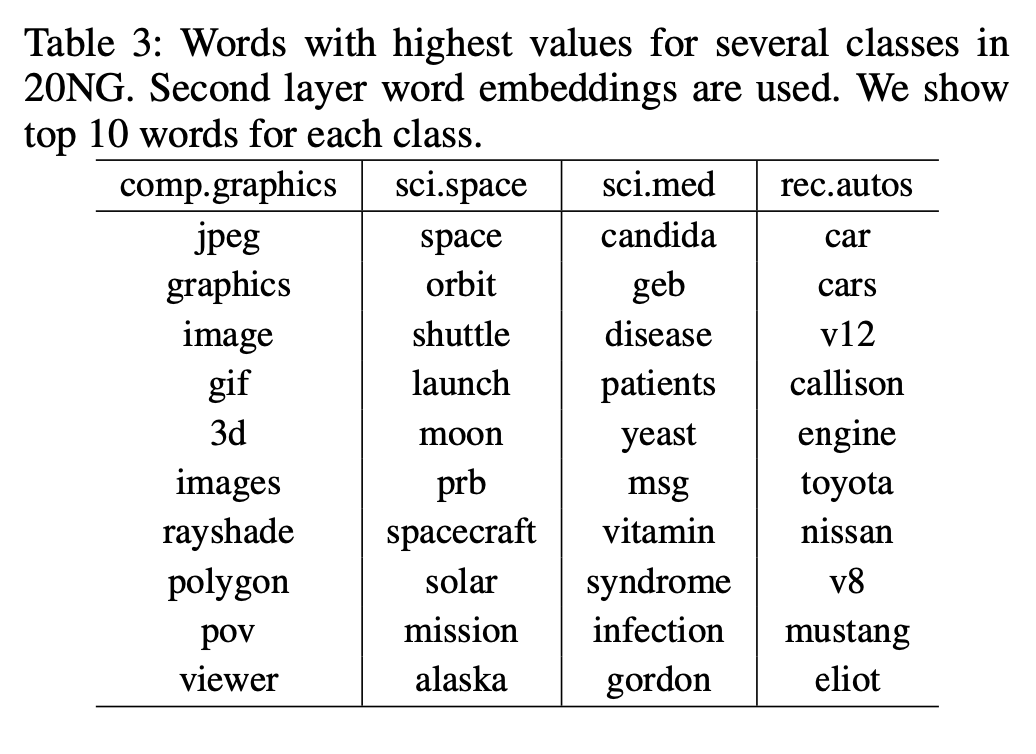
아래 그림은 20NG 데이터셋에 대해 document embedding과 word embedding을 수행한 결과이며 two-layer 결과에서 가장 좋은 성능을 보였음을 확인할 수 있다. 더불어 각 클래스 별로 가장 값이 높은 top 10 단어를 추출하였을 때 Table 3처럼 interpretable한 결과를 얻을 수 있었다.

Discussion
본 논문은 텍스트를 GCN에 어떻게 접목시킬 것인가에 대한 직관을 제공해주었으며, Text GCN이 기존 pre-trained 방식만큼의 좋은 성능이 나온다는 것을 보였다.
그러나 GCN은 Inherently transductive한 성질을 가지기 때문에, test document 또한 GCN 학습 시에 포함되어야 한다는 한계가 존재한다. 그렇기 때문에 unseen data에 대해 embedding을 생성하거나 prediction하는 것이 불가능하다.
이러한 한계를 극복하기 위한 관련 연구들도 존재한다. [Inductive (Hamilton, Ying and Leskovec 2017), FastGCN (Chen, Ma and Xiao 2018)]