Grad-CAM
01 Apr 2018Grad-CAM은 모델이 왜 이러한 결과로 prediction 했는지 이유를 “gradient” 기반으로 visualization 하는 논문이다. 본 포스팅에서는 Grad-CAM을 알아보기에 앞서, Weakly-supervised learning와 CAM의 관점에서 Grad-CAM의 의미를 분석해보고자 한다.
Weakly-Supervised Learning
M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Learning and transferring mid-level image representations using convolutional neural networks. In CVPR, 2014.
“Object Classification 학습만으로도 Object Localization이 가능하다”
Object Recognition과 같은 문제를 해결할 때, 많은 양의 Annotated Image 데이터를 필요로 한다. 예를 들어 “Object가 어느 위치에 있는가?” 와 같은 Segmentation Annotaion을 만드는 일은 매우 많은 손이 필요하다. 본 논문은 비교적 annotation이 쉬운 Object Classification 문제를 학습하고, CNN의 high representation을 활용하여 Object Localization 문제 해결에 적용한다. 이러한 방법을 Weakly Supervised Learning이라고 부른다.
Contrib 1. Weakly Supervised Learning
본 논문에 사용되는 데이터들은 사진 내 각 object별로 존재하는지 Labeling 되어있지만, 어느 위치에 있는지 Positional Annotation은 하지 않고 학습한다. 각 사진마다 여러 Object들이 Labeling 되기 때문에 이는 Multi Label 문제로 볼 수 있고, 각 class 별로 sigmoid하여 문제를 해결할 수 있다. 이를 위해 CNN 구조 마지막 부분에 Adaptation Layer를 제안하였다.
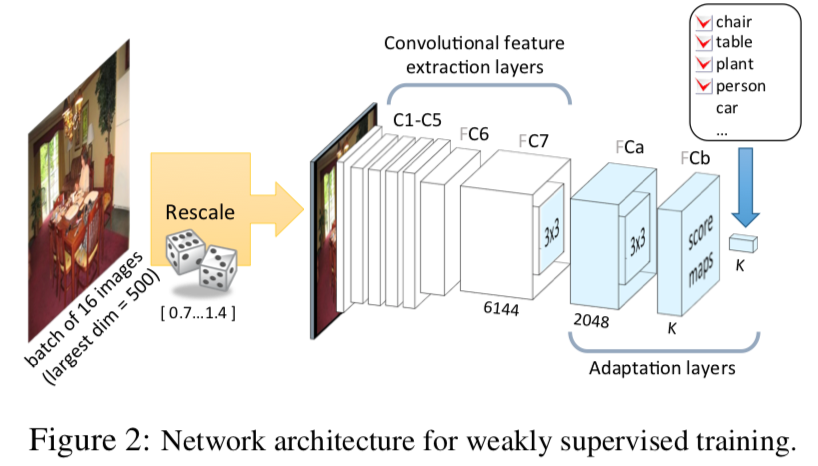
k개의 Multi Label 개수로 Feature Map Channel을 만들고, global max-pooling을 통해 feature map의 채널을 각 label 당 하나의 스칼라로 만든다 (output shape: 1 x 1 x K). 이 후 그 스칼라들을 각각 sigmoid를 통해 각 label 별 존재 유무를 predict 한다.
학습을 위한 Multi Label Loss는 각 class 별 sigmoid cross entropy의 합으로 계산된다. 이러한 Multi Label Loss는 positive label에 대한 feature map channel은 강해지고, negative label에 대한 feature map channel은 약해지는 방향으로 학습되는 특징을 보인다.
Contrib 2. Weakly Supervised Learning의 Classification, Localization 평가
Classfication
Classification은 각 class별 precision을 이용해 Mean Average Precision (MAP)으로 계산하여 평가하였다.
본 논문에서는 아래와 같은 질문으로 Weakly supervised Learning의 우수성을 설명한다.
Global max-pooling말고, mask pooling을 통해 localization label에 해당하는 부분만 마스크를 씌워 학습시키면 classification 성능이 좋아질까?
위 실험에 대해선 별 성능 차이가 없었다. Localization 데이터를 학습해도 Object-level Task로부터 전이된 Weakly Supervised Learning에는 큰 효과를 주지 못하였다. 즉, (localization label이 없는 weakly 데이터로) Weakly Supervised Learning이 가능함을 입증한다.
Localization
Weakly Supervised Learning으로 Classification 학습에 사용된 feature map에서 가장 큰 값에 주목함으로써 Localization 여부를 확인해볼 수 있다. 이는 아래와 같은 방법으로 계산된다.
- Location Prediction Metrics
- Label이 k일 때, 그에 대응되는 k개의 feature map을 input 이미지 크기로 rescale 한다.
(본 논문에서는 단순 interpolation으로 복원) - rescale된 map에서 maximal value가 location label box 범위와 18 pixel 이내에 있다면 correct, 아니라면 false positive라고 평가한다.
(네트워크의 pooling ratio (rescale 오차범위)를 고려해 18 pixel tolerance 설정)
- Label이 k일 때, 그에 대응되는 k개의 feature map을 input 이미지 크기로 rescale 한다.
위 방법을 fully-supervised learning (R-CNN)과 비교하였을 때 거의 비슷한 성능을 보였고, 이는 곧 weakly 데이터를 써도 좋다는걸 입증하였다.
CAM
B. Zhou, A. Khosla, L. A., A. Oliva, and A. Torralba. Learning Deep Features for Discriminative Localization. In CVPR, 2016.
Reference: Blog
CAM은 Weakly-supervised Object Localization 문제에 대해 class별로 왜 이런 결과가 predict 되었는지 이유를 visualization 하고자 한다. 본 논문에서 주장하는 주요 내용은 아래와 같다.
Global Average Pooling(GAP)이 Global Max Pooling(GMP)보다 좋다.
위 M. Oquab et al., 2014 에서는 GMP를 이용한 Adaptation Layer를 거쳐 multi-label 문제를 학습하였다. 본 논문에서는 아래와 같이 GMP와 GAP의 차이를 소개하며, GAP로 대체하였다.
- GAP loss는 전반적인 object identification에 강한 반면,
GMP loss는 object 내 가장 discriminative한 부분에 집중한다. - GAP는 낮은 activation 값이 섞여있을 때 전체 output도 영향을 받지만,
GMP는 낮은 activation이 섞여 있더라도 most discriminative part만 선택되기 때문에 아무 피드백도 받지 못한다.
CAM Architecture
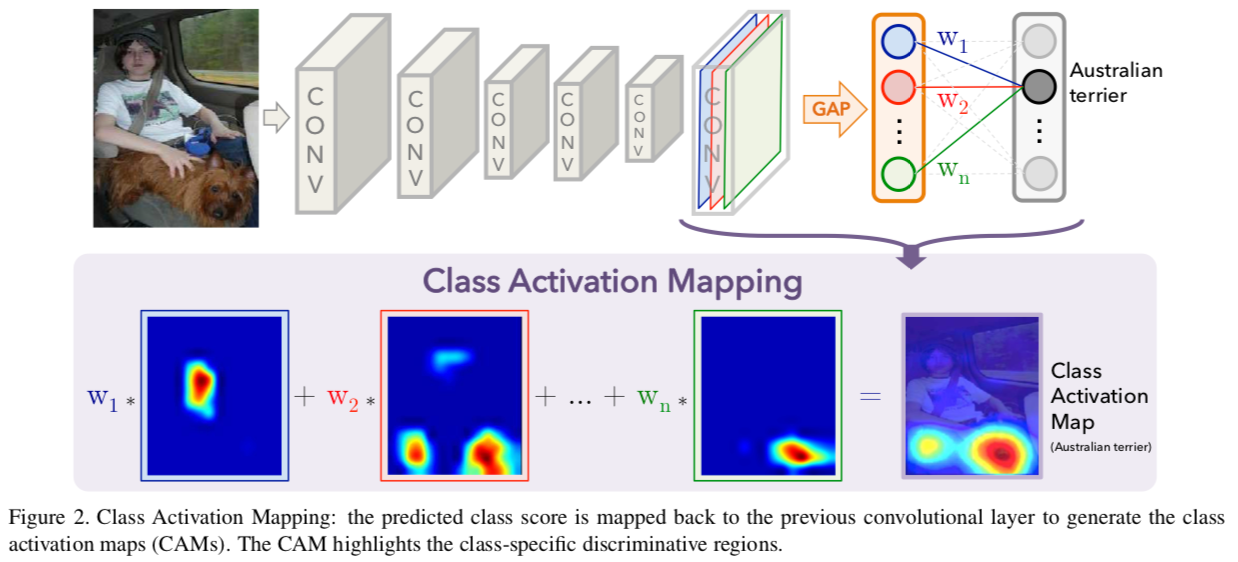
위 M. Oquab et al., 2014 에서는 k개의 feature map을 GMP 연산으로 k개의 scala로 만들어 도출했다.
반면, 본 논문은 k개의 feature map을 GAP 연산으로 k개의 scala로 만든 후, FC layer 하나를 추가해 마지막 Output layer 출력한다. GAP로 계산된 k개의 scala는 k개의 feature map 별로 모든 grid value를 반영하게 도출된다.
이는 결국 k개의 feature map을 선형조합하여 i번째 class(ex. Austrailan terrior)를 predict 하게 됨을 의미한다.
CAM의 원리
$f_k(x,y)$를 k번째 feature map의 x,y grid value라고 했을 때, GAP 연산에 의한 k개의 scala는 아래와 같이 정의된다.
(normalized term은 생략)
k개의 scala를 선형 조합하여 $c$(class)에 대한 predict value를 $S_c$라고 했을 때, 아래와 같이 정의된다.
위 식의 일부를 $M_c(x,y)$로 정의할 수 있다. $M_c(x,y)$는 모든 feature map의 선형 조합이며 이는 곧 $c$(class)에 대한 activation map(CAM) 을 의미한다.
이 때, $M_c$는 feature map의 크기와 같고 이를 입력 이미지 크기로 upsampling해서 visualize할 수 있다.
Localization
Object Localization 영역은 CAM에 20% threshold를 주어 bounding box를 만든다.
Grad-CAM
R.R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh and D. Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. In ICCV, 2017.
기존 CAM은 GAP를 이용해 CNN feature map이 곧바로 softmax layer가 되도록 하였다. 그러나 이런 구조는 CNN Layer 뒤에 추가 Layer를 붙일 수 없어 모델 구조에 제약이 생기고, 이로 인해 적용할 수 있는 도메인도 제한된다.
반면 Grad-CAM은 CAM의 일반화된 버전으로서 gradient information을 이용한 새로운 방법을 제안하고, CNN Layer 뒤에 어떤 구조가 등장해도 가능하도록 한다. VQA, Multi Modal 등 CNN 뒤에 여러 layer가 쌓이는 다양한 곳에 쓰일 수 있다.
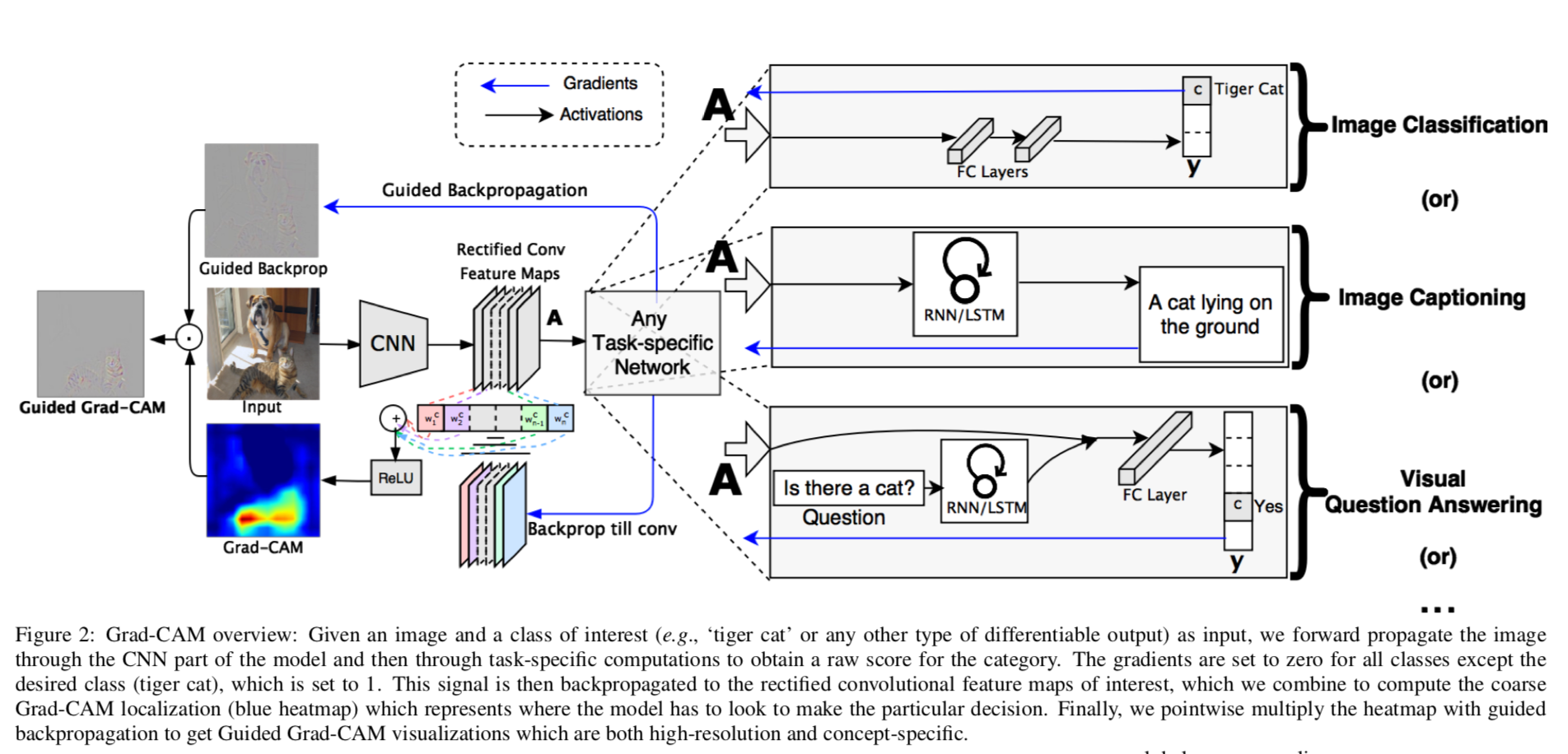
Definition
Grad-CAM에 대한 수식적 정의는 아래와 같다. (이 때, ${1\over Z}\underset{i}{\Sigma}\underset{j}{\Sigma}$는 GAP를 의미한다.)
$\alpha^c_k $는 k번째 feature map($A$) 변화에 따른 $y$ pred 값의 변화량이며, 이는 곧 $c$(class)에 대한 $k$번째 feature map의 중요도를 나타낸다.
따라서 visualize map인 $L_{Grad-CAM}^c$는 아래처럼 정의된다.
이 때, ReLU는 feature map value중 긍정적인 영향을 미치는 것만 살리는 의도가 있다 (visualize를 위해서라도 음수값을 없애야 할 필요가 있다고 생각된다).
Grad-CAM이 CAM의 generalization 버전임을 증명
위에서 작성된 CAM 수식을 Grad-CAM 버전으로 용어를 맞춰보자.
CAM에서 $k$번째 feature map을 의미하는 $f_k(x,y)$는 여기서 $A_{ij}^k$ 이다.
CAM에서의 $c$(class)의 predict value였던 $S^c$는 Grad-CAM 버전으로 아래처럼 정의된다.
CAM에서의 $M_c$는 여기서 $L^c_{CAM}$이다.
이에 따라, $L_{Grad-CAM}^c$와 같은 꼴이고 $\alpha$가 CAM에서는 weight일 뿐이다.
Guided Grad-CAM
본 논문에서는 위에서 설명한 Grad-CAM 기법과 더불어 Guided Backpropagation 이라는 기법을 접목한 Guided Grad-CAM을 소개한다. 기존 Important Pixel Visualization 방법으로는 Guided Backpropagation 방법과 Deconvolution 방법(High Resolution 기법)이 존재했다.
Guided Backpropagation의 경우, Gradient를 거꾸로 추적하면서 입력 이미지에 대해 Pixel Space Gradient를 보여준다. 하지만 class-discrimitive한 측면에서는 성능이 좋지 않아 Localization이 잘 안되는 단점이 있다.
Deconvolution의 경우, output에서부터 거꾸로 deconv하면서 올라가는 방법이다.
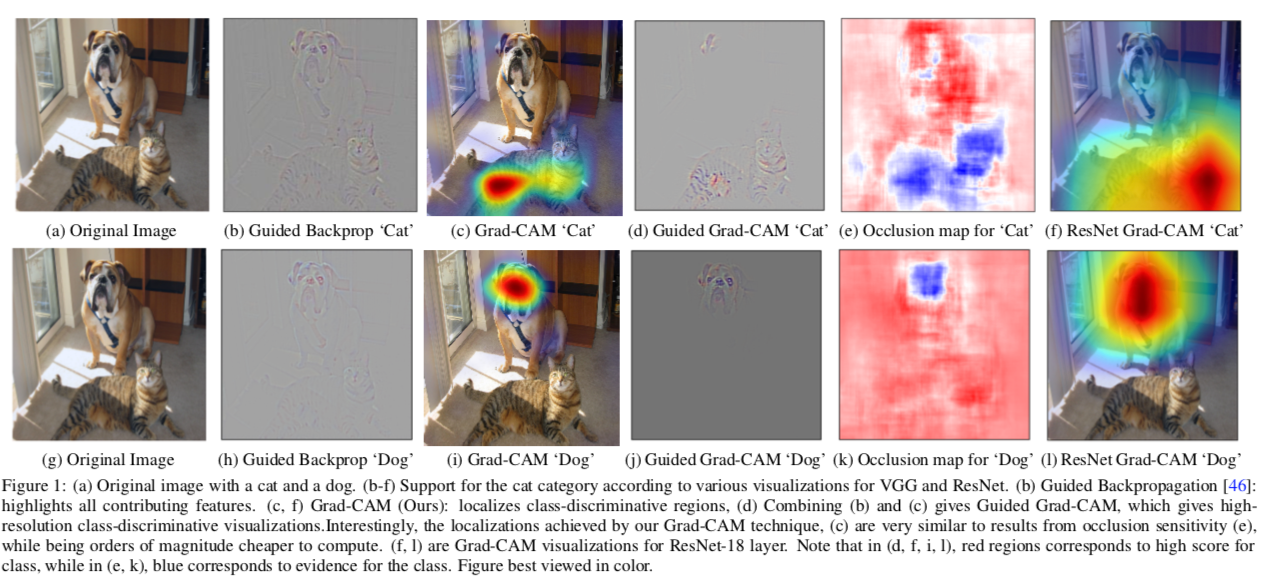
위 그림에 따르면 Grad-CAM이 class-discriminative하고 localize visulization이 잘 되지만, 다른 Pixel Space Gradient Visualization 기법 (Guided Backpropagation, Deconvolution)같이 fine-grained importance를 보여주는 능력은 없다. 또한 Grad-CAM은 Upsampling(본 논문에서는 bi-linear interpolation을 사용) 방식이기 때문에 low resolution 하고, 때문에 Figure 1c에서 보면 히트맵이 고양이의 형상을 완벽히 커버하지 못한다.
이를 해결하고자 Guided Backpropagation 결과와 Grad-CAM 결과를 합쳐서 사용하면 고양이 부분을 더 선명하게 찾을 수 있다. Deconvolution와 Guided Backpropagation 모두 실험하였으나 Guided Backpropagation이 덜 noisy해서 이를 채택하였다.
Evaluation
본 논문에서는 Grad-CAM을 다양한 관점에서 평가한다.
Weakly Localization
CAM은 GAP가 있는 CNN 모델만 가능하므로 VGG16에서 뒤쪽 FC Layer는 모두 제거하고 비교한다. 때문에 본래 classification 성능도 떨어지게 되고, Localization Error도 Grad-CAM 보다 비슷하거나 낮다.
Pointing Game
Segmentation 할 때, pixel 단위로 얼마나 overlap되는가 비교한다. Baseline 알고리즘의 경우 처음보는 label을 줘도 무조건 어딘가를 Segmentation하는 반면, Grad-CAM은 segmentaion을 하지 않아서 accuracy가 더 좋다. (즉, Grad-CAM이 True Negative가 더 높다.)
Counterfactual Explanations
Grad-CAM의 정의에서 ReLU를 통해 양수만 남기는 과정을 거쳤다. 본 논문에서는 Gradient를 음수로 뒤집으면 어떤 의미가 있는지 분석해보았다.

Figure 6b는 고양이라고 판단하는데 방해가 된 요소가 개 부분임을 보여주고, Figure 6c는 개라고 판단하는데 방해가 된 요소가 고양이 부분임을 보여준다. 이를 통해 양수 Gradient를 사용하는 것이 정말로 $c$(class)를 predict하는데 필요한 중요도를 의미한다는 것을 알 수 있다. 더불어 음수 Gradient를 분류가 틀리게 하는 방해요소를 찾는 곳에도 사용할 수 있다.
Image Captioning
실험을 위해 VGG16 모델로 Captioning Visualization 하였다. Explicit한 Attention Layer가 없음에도 불구하고, Grad-CAM을 이용하면 Caption에 해당하는 부분을 잘 highlighting 하였다. 직접적으로 Localizaion을 하는 모델과 비교해봐도, Grad-CAM의 Caption highlighting 성능이 나쁘지 않았다.
Grad-CAM for Text
Reference: Code
이러한 Grad-CAM은 텍스트 분류에서도 마찬가지로 사용할 수 있다. Y. Kim, 2014 와 같은 1D-CNN 모델도 똑같은 feature map을 가진다.
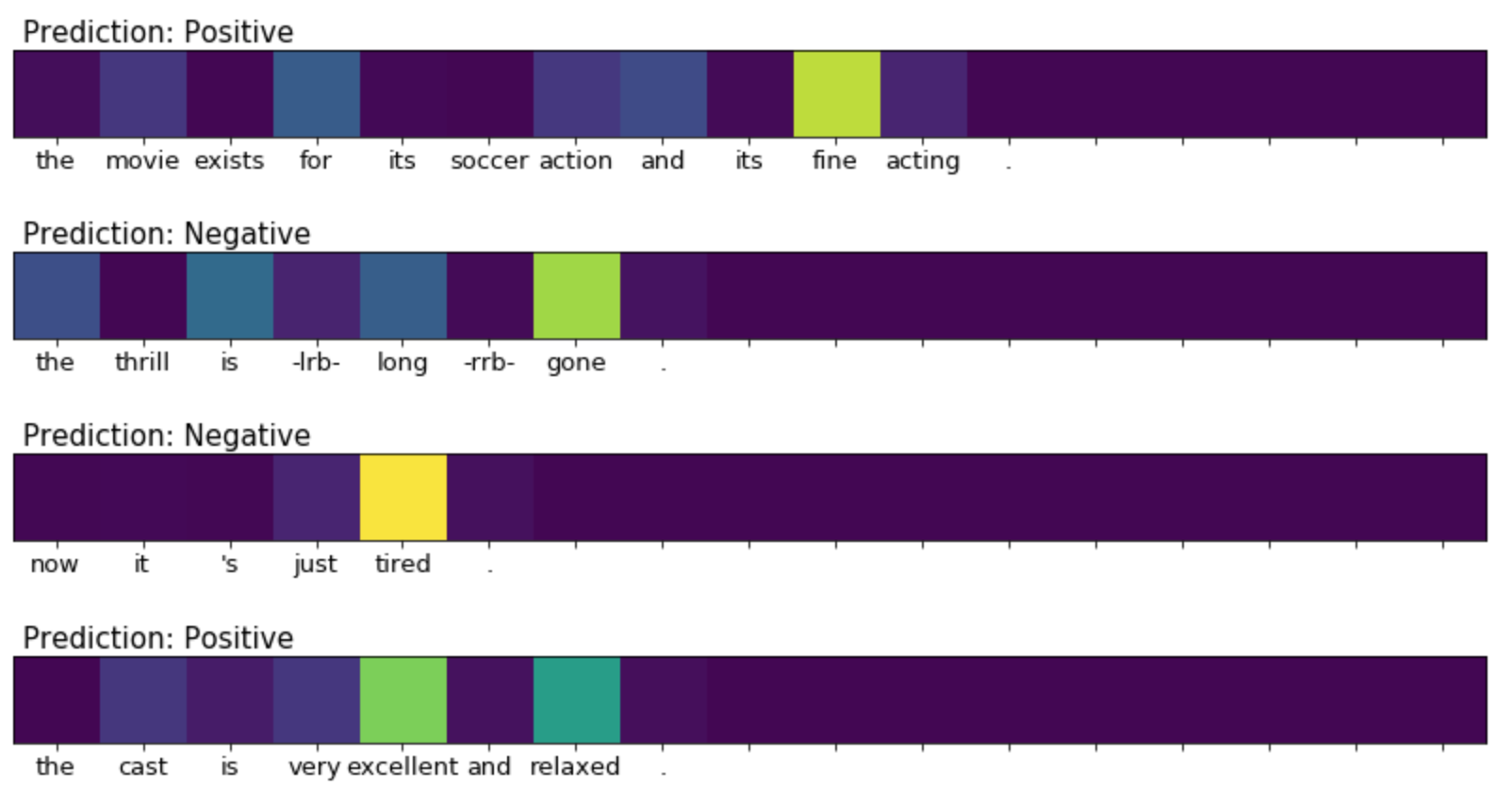
위 그림은 Stanford Sentimental Treebank(SST) 분류에 대해 Grad-CAM을 적용한 결과이다. “excellent”이라는 단어에 의해 Positive라고 판단하고, “tired”라는 단어에 의해 Negative로 분류된 결과를 확인할 수 있다.
이에 대한 code는 grad-cam-text에서 확인할 수 있다.