ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators
29 Mar 2020K. Clark, M. Luong, Q. V. Le, and C. D. Manning. Electra: Pre-training text encoders as discriminators rather than generators. In ICLR, 2020.
Method
본 모델은 GAN에서 아이디어를 착안하여 generator G와 discriminator D로 구성된다.
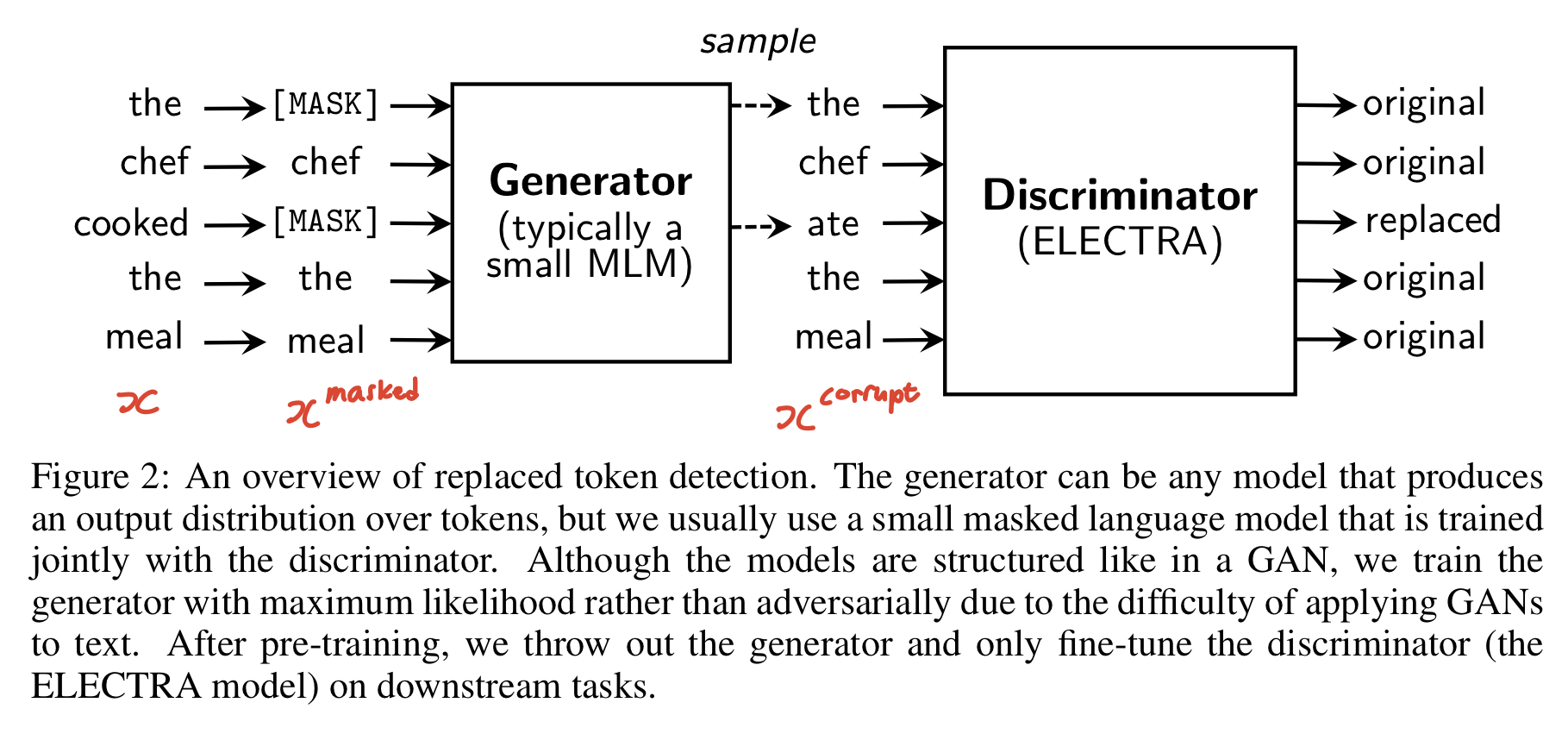
Generator
먼저 Generator $G$는 기존의 MLM 방식의 모델을 사용하고, $x$ sequence에서 random position으로 선택된 $m$ (masked-out token) 을 [MASK]로 대체한다. 이 과정을 통해 masked-out된 토큰을 $x^{masked}$라고 정의한다.
Generator는 대체된 token을 원본 token으로 복원하는 것을 목표로 한다.
즉, $ p_{G}(x_{i}|x^{masked}) $ 를 높이는 방향으로 학습하며, 아래와 같은 loss를 따른다.
Discriminator
Discriminator $D$ 는 generator sample의 masked-out token 중 일부를 다른 단어로 손상시켜 입력으로 받는다. 그리고 각 단어별로 원본 단어인지 아닌지를 학습하게 된다. 이를 $x^{corrupt}$ 라고 정의하였으며, 아래 섹션에서 코드와 함께 자세히 살펴볼 예정이다.
$D$가 맞춰야하는 대체된 토큰은 $x^{corrupt}$라고 정의한다. $D$는 아래와 같은 cross entropy로 학습한다.
Key Differences between GAN and ELECTRA
본 아이디어는 GAN에서 착안된 아이디어지만, ELECTRA는 GAN과 몇 가지 차이점을 가진다.
1. 생성된 이미지는 무조건 “fake”라고 간주하는 GAN과 달리, ELECTRA는 $G$가 correct token을 생성할 경우, $D$에서 “real” 단어로 사용된다.
위 Figure2에서 알 수 있듯, $G$가 생성한 각 단어 별로 $D$는 original, replaced 여부를 판단한다. 첫번째 [MASK] 부분이었던 “the”가 correct token으로 생성되자 $D$는 이를 “real” 단어로 학습하는 모습을 보인다.
2. G는 adversarially하게 D를 속이기 위한 학습을 하는게 아니라, 원래 단어로 복원시키는 maximum likelihood ( $p_{G}(x_{i}|x^{masked})$ ) 를 학습한다.
GAN은 $G$와 $D$가 adversarially하게 학습을 하고 이는 sampling을 back propagate 하는데 어려움이 따른다.
이는 ELECTRA에서도 비슷한 문제가 발생하며, 아래 코드와 함께 살펴보자.
# Generator
embedding_size = (
self._bert_config.hidden_size if config.embedding_size is None else
config.embedding_size)
if config.uniform_generator:
mlm_output = self._get_masked_lm_output(masked_inputs, None)
elif config.electra_objective and config.untied_generator:
generator = self._build_transformer(
masked_inputs, is_training,
bert_config=get_generator_config(config, self._bert_config),
embedding_size=(None if config.untied_generator_embeddings
else embedding_size),
untied_embeddings=config.untied_generator_embeddings,
name="generator")
mlm_output = self._get_masked_lm_output(masked_inputs, generator)
else:
generator = self._build_transformer(
masked_inputs, is_training, embedding_size=embedding_size)
mlm_output = self._get_masked_lm_output(masked_inputs, generator)
fake_data = self._get_fake_data(masked_inputs, mlm_output.logits)
self.mlm_output = mlm_output
self.total_loss = config.gen_weight * mlm_output.loss
# Discriminator
disc_output = None
if config.electra_objective:
discriminator = self._build_transformer(
fake_data.inputs, is_training, reuse=not config.untied_generator,
embedding_size=embedding_size)
disc_output = self._get_discriminator_output(
fake_data.inputs, discriminator, fake_data.is_fake_tokens)
self.total_loss += config.disc_weight * disc_output.loss먼저 $G$는 masked-out된 단어를 원래 단어로 복원시키는 maximum likelihood 를 학습한다. 때문에 위 코드에서도 알 수 있듯 $G$의 학습 과정에서는 fake를 생성하는 단계가 없다.
그러나 $D$의 입력인 $x^{corrupt}$를 만들 때, 아래 코드처럼 $G$의 단어 별 masked-out token들의 logit에 gumbel noise를 가해 일부러 fake word를 생성한다. 이를 본 논문에서는 generator sample 이라고 표현하였다. 이러한 gumbel nosie를 주는 과정에서 아래 코드와 같이 sampling 단계가 포함되고, GAN에서와 마찬가지로 sampling을 back propagate 하는데 어려움이 생긴다. 이를 위해 $G$를 RL로 학습하는 것도 시도했지만 결과적으로 maximum likelihood로 학습하는게 성능이 더 좋았다.
def sample_from_softmax(logits, disallow=None):
if disallow is not None:
logits -= 1000.0 * disallow
uniform_noise = tf.random.uniform(
modeling.get_shape_list(logits), minval=0, maxval=1)
gumbel_noise = -tf.log(-tf.log(uniform_noise + 1e-9) + 1e-9)
return tf.one_hot(tf.argmax(tf.nn.softmax(logits + gumbel_noise), -1,
output_type=tf.int32), logits.shape[-1])3. GAN가 달리 ELECTRA는 입력으로 별도의 noise vector를 주지 않는다.
Loss
최종적으로 ELECTRA는 $G$와 $D$의 loss를 합쳐 학습한다.
이 때, $D$의 loss는 $G$까지 back propagate하지 않는다. (generate sample을 D의 입력으로 주는 과정에서 sampling이 단계가 존재하기 때문에 back propagate이 불가능하다.)
Experiments
Model Extensions
Weight Sharing
본 논문에서는 generator와 discriminator의 weight sharing을 통한 pre-training으로 성능 향상을 제안한다. 만약 $G$와 $D$의 크기가 같다면 weight를 sharing하는 것이 가능하지만, 작은 크기의 generator를 쓰는 것이 더 효과적이었다. 작은 generator를 쓸 경우, $G$와 $D$가 embedding만을 sharing 하는 것이 좋다고 주장한다.
Smaller Generator
만약 generator와 discriminator의 크기가 동일하다면 ELECTRA는 masked language modeling보다 약 2배많은 계산을 수행해야 할 것이다. 이 때문에 본 논문에서는 smaller generator를 제안한다. Figure 3과 같이 결과적으로 generator의 dimension은 discriminator의 1/4~ 1/2 수준이 가장 좋았다.
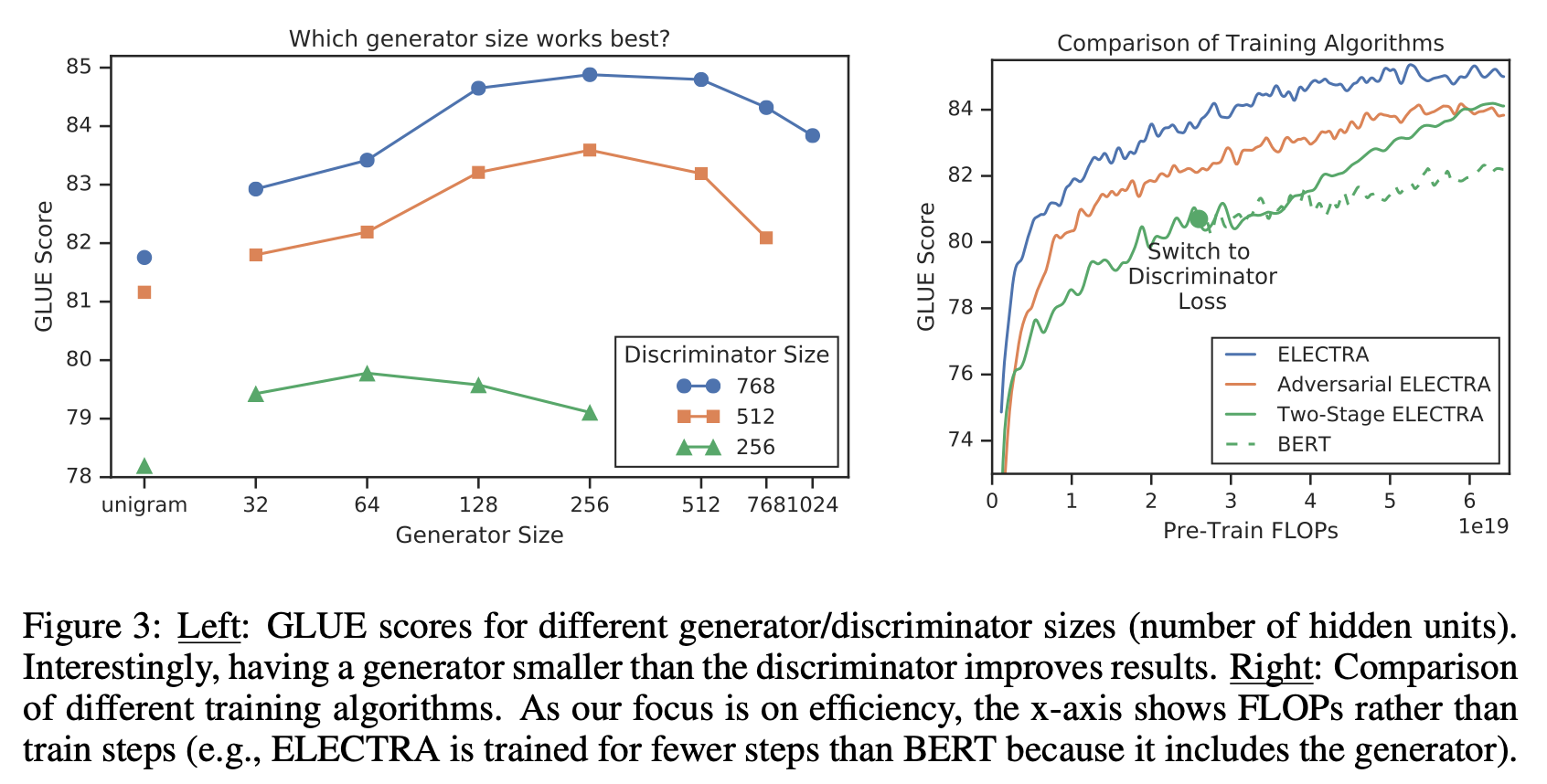
Training Algorithm
ELECTRA는 두 가지 Loss에 대해 Joint Training으로 학습을 진행하였다. 그러나 이와 별도로 다양한 학습 방법을 시도해보았으며 그에 대한 비교 평가를 진행하였다. 그 중 하나로 Two-Stage로 학습한 방법이 있으며 아래와 같은 단계로 학습한다.
- $\mathcal{L}_{MLM}$로 $G$만 학습한다.
- $G$의 weight로 $D$를 초기화 한 후, $G$는 freeze 시킨 채 $D$만 $\mathcal{L}_{Disc}$로 학습한다.
이 때, $G$의 wight로 $D$를 초기화하는 것은 $G$와 $D$가 같은 크기일 때만 가능하다. 만약 $D$를 이와 방식으로 초기화하지 않는다면, $G$가 $D$보다 너무 많이 학습된 상태이기 때문에 $D$가 잘 학습이 안될 수도 있다.
이를 위해 Joint Training을 통해 generator가 덜 학습된 상태에서 discriminator가 학습을 시작하도록 커리큘럼을 제공해주었다.
위 Figure3을 통해 학습 방법에 따른 성능을 비교할 수 있다. 먼저 $G$와 $D$가 단절된 채 학습하는 Two-Stage 방식으로도 기존 BERT를 능가하는 성능을 보인다. 그리고 앞서 언급한 RL 기반의 Adversarial 방식은 Two-Stage보다 좋은 성능을 보였다. 최종적으로 maximum likelihood 기반으로 Joint Training을 수행한 방식이 가장 좋은 성능을 보였다.